M Deepdive: Buffer
Hello again everyone.
This time, we are going to take a look at a fairly obscure / advanced little M code functionality, Buffer.
What is it & why do I care?
Buffer is a functionality you can call in M, which essentially loads the query step you reference into memory. Of course, this isn’t a piece of code you’ll be using all the time, but the ability to load a query into memory can really help a handful of tricky problems. By loading a table into memory you are, in essence, making it a fixed object that other queries, or even query steps, can reference. This can either fix certain operations, such as sorting, or help improve query performance.
One quick note about using this - it isn’t in any of the GUI menus so if you want to use you’ll have to get into the advanced editor and write it yourself. However, if you are reading this blog, this is probably something you are pretty familiar with I’d expect. For reference the syntax is
#"Add a Buffer!" = Table.Buffer("Calculation step to buffer")
The happy little exclamation mark is optional.
Fixing a Table in Place
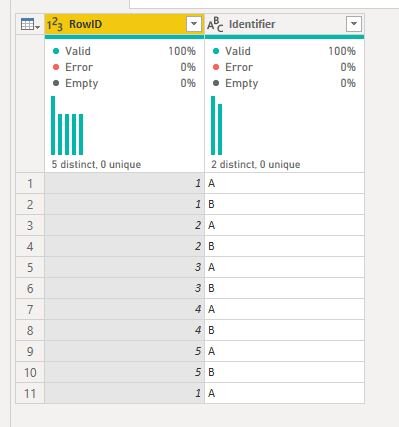
I’m going to reference this later so lets call it the “Raw Table”
Here is a really simple data extract. You can see we have a row ID and an identifier. This case is obviously going to be a weird example one, you would never really do in reality, but it will give a great example of how PowerBI actually runs under the hood.
So, our bizarre usecase is, we want to remove all duplicate RowID while prioritising keeping the rows with an identifier of “B” (told you this would be a weird example!).
Here is the first insight about how PowerBI works under the hood. If you ask PowerBI to remove duplicates, it will work from the bottom up. As an example, if we remove duplicates based only on the RowID (ignoring identifier) then PowerBI has to make a decision as there are three rows with a value of 1. Because we are asking it to remove duplicates based only on the contents of the RowID column, it has no way to judge which of the rows with a RowID of 1 it should keep, or get rid of. So, by default it will do it by sort order - the first instance of a RowID 1 will be kept, and the other rows discarded.
So if we sort our table to have B on the top (in this case, just sorting RowID into descending order), this should be an easy job -

Callback is imminent - lets call this one “Sorted Table”
Knowing what we know about how PowerBI works, we should expect the first row it’ll find for RowID 1 is row 4 in the screenshot, with an ID of B. So now I’ve sorted my data, I’ll just remove duplicates (Table.Distinct) based on the RowID -

But what PowerBI will actually return. This initially seems super weird! Here is my code, so you can see I’m not cheating - this really will happen!

Feel free to try this yourself!
So what is going on here?
PowerBI will always try to be as efficient as possible in resolving your queries. Also, it won’t necessarily follow the query you’ve written in sequential order, if it thinks there is a better, less process intensive way to run it.
So, even though in my code I sorted my data, and then applied my Table.Distinct to the query step in which I sorted the rows, PowerBI isn’t executing the steps in that order.
This is because sorting is a process intensive activity. Therefore PowerBI removes the duplicates first in order to have a smaller amount of data to sort. The result of this is that it can process the query faster than if it were to run the query in the sequence I wrote. For most cases this is fine, as it often doesn’t really matter, and it’s a nice feature that it will automatically try to optimise your query for you.
Unfortunately in this case (and I’m sure many others!) this has actually resulted in the query returning a result we weren’t expecting, or wanting, as PowerBI sorted the table when it was in the Raw Table state, not the Sorted Table (I told you there would be a callback!).
This is where buffering comes in. If you use the Table.Buffer function then PowerBI is forced to load the table into memory before running any subsequent steps. Now, PowerBI will still choose how it runs the subsequent steps, prior to the buffer statement, but it essentially creates a break in your query, whereby PowerBI must complete all the previous steps to the buffer before it can run the subsequent steps.

So in my code, now I’ve added this step, PowerBI is forced to buffer the #”Sorted Rows” before it can action #”Removed Duplicates”.

And there we go! Result.
While this example is obviously pretty limited in real world application, this principle is not only great for making sure your sorts are applied at the stage you want them to be, but also for fixing a query step at a certain point in a query and also for forcing later query step(s) to work from the buffered table - this could be really helpful if you are using a loop in M, as you can buffer a query that you use to feed a parameter in your loop.
A little point about this I recently learned - if you “reference” a query, it doesn’t work how you might think. I’d expect that it would run the first query, then use the results of that as the source for the second query. However, what actually happens is the first and second query are run independently. In other words, when query 2 runs, it doesn’t use query 1 as a source, it runs all of query 1 until it gets to the point you referenced it, and then it runs the query 2 code on top. This is obviously not super efficient. You probably wouldn’t notice this if the tables are small, but if you have a report with loads of data adding this kind of bloat to a query can be problematic.
This is something that Buffer can fix - if you have the right set of circumstances. If you are working with a sequential query like in the previous paragraph, buffer will fix the first table and work off that.
However, if you have multiple queries running off one query, Buffer won’t help. This is because Buffer can only be applied within the same query execution.

So to clarify - if your query structure is like the one on the left, where it’s purely sequential, Buffer should help fix that point. But if your queries are in different executions, like the flow on the right, Query 1 will be run twice, and it will buffer twice, which would actually bloat your query more.
This would not be ideal - so if you are referencing a query multiple times it would be better to move the initial query into a dataflow (as per Microsoft’s recommendation)
Final point - unless you need to, don’t buffer tables as it takes up memory and adds an extra step to the query!
Anyway, hopefully you found something useful in this blog; happy querying!